
- From “it is documented” to “AI can understand it”
- How to evaluate the structure of documentation?
- Ending: a five-dimension rubric
- Two tools so improving this does not become torture
- Iterations, experiments, and progressive refinement
- References and standards
We ask AI agents to do real analytical work: write SQL, answer business questions, detect patterns, or… anything having to do with data models. Let’s assume your schema is documented well enough for a person who already knows the context, which, in most cases, is already quite a heroic assumption. But is it also documented well enough for an agent with no previous context?
If there is implicit knowledge, the agent will make decisions and assumptions to generate SQL that looks perfectly reasonable. Everything may compile, run, and even return plausible numbers. But can I be sure the agent is not making a semantic mistake? Maybe it does not know that a status field only allows four valid values, and while we’re here, maybe it does not understand what each one means, whether they affect other columns, or whether they imply a different way of reading the results. Maybe it interprets a nullable date as “unknown data” when in fact it means “this never happened”. Maybe it sees three fields ending in _id and assumes the primary key is the combination of all of them, when it absolutely is not. None of that is exactly a model failure. Mostly, it is a documentation failure.
Let’s take an example. Say I’m working with a merchants’ data model. You start building a churn prediction model, and the first thing the model assumes is that 15 days without sales means churn. Nice. Very tidy. Suspiciously tidy. Then it turns out that a meaningful percentage of merchants work with monthly subscriptions or sell tickets for events that happen every few weeks, so their sales naturally come in bursts. If you have the tacit knowledge of how your merchants operate, great. If you do not, you may never realize the model is predicting churn based on a significant percentage of positives that are not positives at all. Or you may realize too late, when there is no way to make a decent model, and you start digging for reasons. The first is a Trojan tragedy. The second is a Turkish soap opera.
So the question is: can I tell to what extent a schema is prepared for an AI agent to understand it and use it well?
From “it is documented” to “AI can understand it.”


“It is documented” is a vague description. “AI agents can understand it” is still a bit fuzzy as a definition, but at least it points in a direction and defines clear cases of non-adherence: when agents slip and make plausible but wrong assumptions. I hear you, but is there any practical way to formulate agent readiness?
Documentation evaluation frameworks
Yes, of course there. We can create a battery of questions and use two models: a respondent model that uses the schema documentation as context and loads on demand whatever else it needs, and a judge model that analyses the response and scores it against a rubric the respondent does not have access to — for example, using something like G-Eval in DeepEval.
This is robust because it checks accuracy empirically: given this documentation, is the model capable of producing correct answers as expected? But it is also heavy and limited. It is limited because it is compared against a specific set of questions, because the measurements depend on the LLM model used to answer, and even on each run. And above all, what really kills me is that it is a very heavy method because I have to define the questions and answers upfront.
And something lighter?
A structural check of the documentation
We can do something lighter, and something that is useful and covers what is needed in the vast majority of use cases. What if we simply ask: does this documentation have the structural properties that make coherent answer generation possible, regardless of the question? We are talking about a structural check. Neither of the two approaches subsumes the other. Testing tells you whether the questions you chose were answered correctly, while a structural check tells you whether the structure itself is solid. They are complementary. But this second one is much more direct and much easier to implement.
So agent readiness means this: to what extent a schema allows an autonomous agent to understand and reason correctly about the data without prior domain knowledge, without follow-up questions, and without wasting context because of ambiguity. The first step — and it is often ignored — is that if it is not understandable for a human, it will not be for an agent either. Don’t overcomplicate it.
So then, what does it mean to reason correctly? We can reverse-engineer it from the risks or scenarios of incorrect reasoning, for example:
- Disambiguation: there are similar tables in the data warehouse that serve similar, but not identical, purposes. Using the wrong table does not throw an error; the agent simply gives you the wrong answer very confidently.
- The meaning is hidden. Much of a table’s tacit definition — its grain, freshness, what it excludes — lives in pipeline code, not in the columns or schema documentation. So an agent might discover it… if it has a reason to inspect the pipeline. But if the table looks documented, or if it can make plausible assumptions, it probably will not. And then it will make a mess.
- Silent failures. Many-to-many joins inflate row counts. Unmanaged nulls distort aggregates. Again, I will not get the uncomfortable but friendly warning of an error. I will get apparently correct results that are not correct at all.
- The context moved out of the table, but left the lights on. It looks like the tables explain the meaning — the agent is confident it has everything it needs — but they are not up to date. A metric changed. A process was updated in a way that changes what the tables now contain. That context may live in Slack threads, project docs, conversations, internal posts… but it is not where it should be for the agent to be aware of it.
How to evaluate the structure of documentation?
Starting from the risks or scenarios we want to avoid, we can build a checklist with very, very concrete things. And as we discover more, we can add new elements. That is, in my opinion, the point: not to pretend we will make it perfect on the first go, but to refine the list iteratively. And then, of course, apply common sense: there are no absolutes. It is very possible that such a checklist will contain elements that are neither necessary nor convenient, depending on the case. But it is still worth thinking about them, even if only to decide not to apply them.
A few examples of elements in a checklist to ensure the structure improves the readability of a data model might include:
- Can the agent figure out how to join tables without guessing? In other words, are PKs and FKs explicitly marked? Has it been checked that what is marked as a key is actually unique?
- Are the valid values of a categorical field explicitly documented?
- Is it understood — and by “understood” I really mean “explicitly described” 🙂 — what
nullmeans in business terms, not only in database terms? - Is it described where the data comes from and what it is later used for, especially when the same field exists in several upstream tables, or because the downstream description does not make clear whether something coming from this table was used?
- Is the grain of the table known?
The more of those questions the schema answers by itself, the less the agent has to improvise. Remember: improvised SQL films belong to the horror genre.
Ending: a five-dimensional rubric
More than measuring readability or agent readiness in the abstract, the idea was to compare tables against one another, or even the same table before and after changes. What I did was create a rubric with five prioritized dimensions, each with stepwise scores from 10 to 30, totaling 100 points. The score is proportional: you look at what fraction of fields or tables meets each criterion and multiply it by the maximum score of that dimension. Is the scoring arbitrary? Without a doubt. But it has no incense, no magic, and it is very clear. Which is already saying quite a lot.

And after scoring, we can also define — again, arbitrarily ¯\_(ツ)_/¯ — a few buckets or score groupings to establish some sort of prioritization criterion for changes or comparisons.
| Score | Assessment |
|---|---|
| 80–100 | 🟢 AI-ready |
| 60–79 | 🟡 Useful with caveats |
| 40–59 | 🟠 Needs work |
| 20–39 | 🔴 Critical gaps |
| 0–19 | ⚫ Not ready for AI at all |
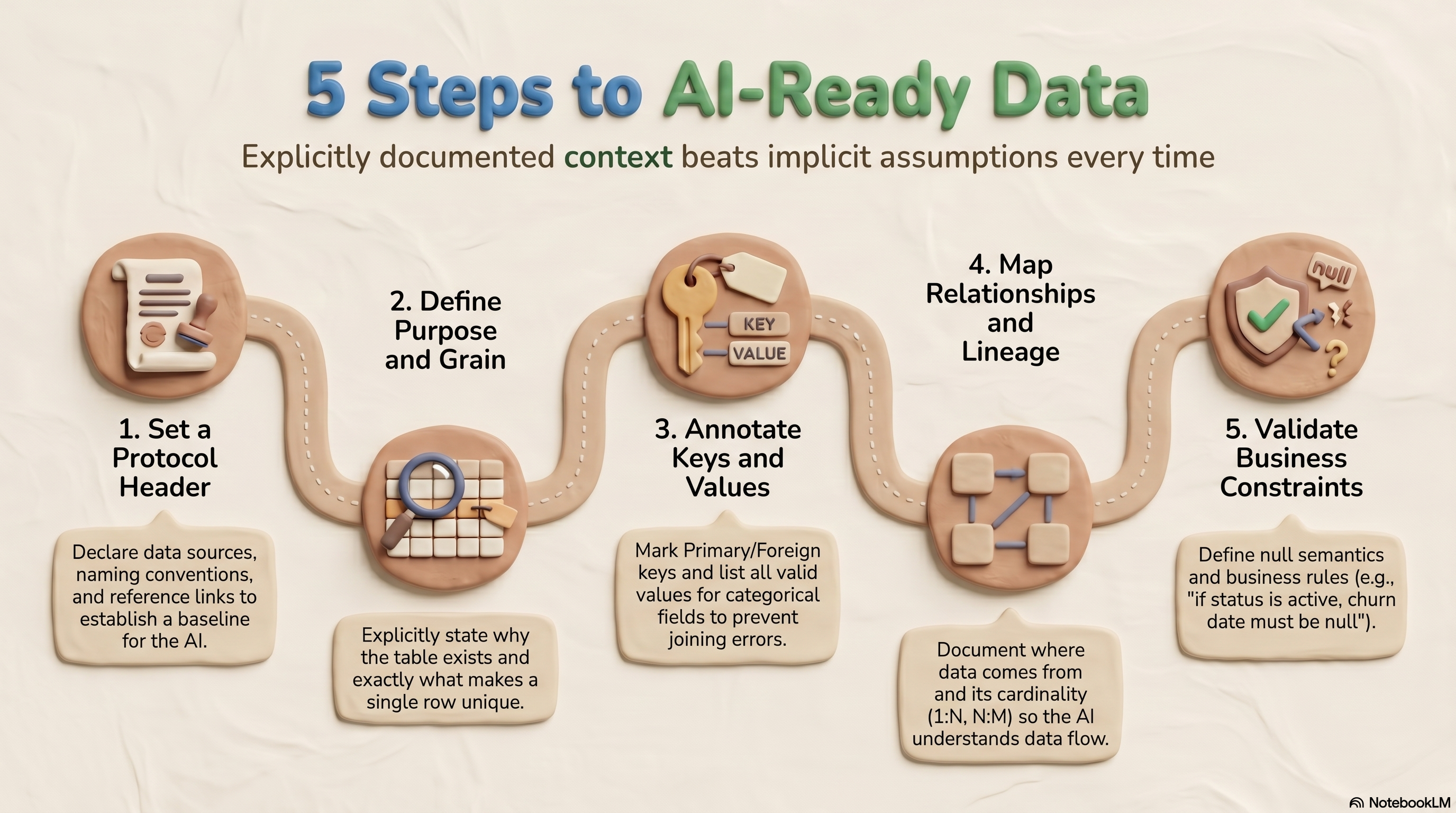
1. Structural documentation (25 points)
- Protocol header (3 pts): format, version, and conventions declared at the start.
- Field-level documentation (7 pts): meaningful annotations explaining what each field represents.
- Table-level documentation (8 pts): purpose, grain (what makes a row unique), and audience (who uses this table).
- Nullability declaration (2 pts): explicit nullable or required markers.
- Null semantics (5 pts): the business meaning of
nullis documented for nullable fields; for example, “nullmeans the user has never logged in”.
Before:
After:
2. Semantic richness (30 points)
- Primary keys are all explicitly marked and unique (8 pts)
- Foreign keys with explicit references (6 pts): FK annotations are declared, not just naming conventions.
- Categorical fields with explicitly enumerated options (6 pts): finite sets of values are declared explicitly.
- Calculated fields with formulas (5 pts): if a field is calculated, for example
mrr_per_user = mrr / active_users, the formula is documented. - Cross-references and shared definitions (5 pts): Documentation inheritance towards external schemas and explicit references to upstream tables is used.
Before:
After:
Before:
After:
3. Relational context (20 points)
- Lineage (6 pts): where the data comes from and where it goes.
- Cardinality (5 pts): documenting 1:1, 1:N, and N:M relationships so agents know whether a join may multiply rows.
- Explicit join keys (5 pts): Can the agent determine how to join without guessing?
- Data flow narratives (4 pts): refresh cadence, latency expectations, and pipeline dependencies.
4. Constraint validation (15 points)
- Uniqueness constraints (5 pts): not just an
idfield, but explicit uniqueness declarations. - Business-rule validations (4 pts): domain logic such as “if
status = 'active', thenchurn_datemust beNULL”. - Verified referential integrity (6 pts): foreign keys are declared, and referenced tables exist.
5. Human-AI comprehension (10 points)
- Terminology clarity (4 pts): domain terms, acronyms, and internal names are defined.
- Business context (3 pts): why the table exists, who uses it, and what decisions it supports.
- Edge-case documentation (3 pts): historical gaps, quirks, and exceptions are explicitly called out.
Two tools To automate the process
Lovely. We now have a way to score schemas. But nobody wants to review them by hand, this would be torture. I built two skills.
1. Evaluate Schema for AI Readiness
This skill runs the rubric over a schema file and returns a prioritized list of concrete recommendations. You can point it at a file in a repository or paste the schema directly, and it will tell you not only the score but also what makes sense to fix first. Obviously, I am showing my own prioritization and scoring here. If you want to give more weight to some things over others, you simply change the weights.
2. Schema improvement
This one is modular. Instead of trying to improve everything in one giant pass, it works in phases, and I can run one or several phases — or even part of a phase — over one or several tables in a schema:
- Phase 1: add a protocol header with data sources, table types, naming conventions, and reference links
- Phase 2: document each table with purpose, grain, and intended audience
- Phase 3: document fields, identify primary keys, annotate foreign keys, and detect categorical fields that need valid-value enumeration
- Phase 4: remove duplicated documentation by pointing repeated fields to a canonical source
- Phase 5: inspect production data to detect fields marked nullable that are in fact never null, and adjust the schema accordingly
The design principle behind this is progressive disclosure: each phase loads only the context it needs. That makes the process lighter, more reliable, and easier to parallelize as schemas grow.
Learned lessons from Iterations, experiments, and progressive refinement
After several iterations and experiments, refining both skills, no schema reached the “AI-ready” threshold I set. Again, I reckon the threshold was arbitrary, but in any case, it expressed what I wanted my schemas to be, and I expected at least one of them to get there. But not a single one. Not one.
It may sound dramatic, but the pattern was fairly mundane. Many schemas had decent field-level comments. Some included table descriptions. But what was often missing were precisely the pieces an agent depends on most when it cannot ask for clarification:
- explicit relationship declarations
- null semantics
- enumerations of valid values
- upstream/downstream lineage and context
- business meaning, especially around edge cases
That is to say: exactly the things that are obvious to the person who has spent months with a data source, and completely invisible to someone new to that business. Or to a model. But time was not wasted 😀 I learned a great deal of lessons that I can summarize into these three
1. Explicit beats implicit
If a foreign-key relationship is not explicitly documented, something big is missing. I know, in most cases, the field name makes the join obvious. And sometimes it does not. An agent does not have your tacit knowledge, the team’s memory, or those six months of “ah yes, this column is weird because of a migration two years ago”.
2. Null semantics matter enormously
nullable: true tells an agent almost nothing. But documenting something like “Null if the customer has never upgraded” — that is gold. That difference changes filters, aggregations, and interpretation. It is the difference between “missing data” and “meaningful absence”, one of those distinctions that can quietly wreck an analysis without you noticing.
3. Grain and audience should live in the schema
Short notes like “one row per customer and subscription period” or “used for financial reporting” prevent a surprising number of wrong joins and, much worse, dubious conclusions. This helps humans too, of course. Humans are great because they complain 😀 AI just fill the gaps, and by the time you realize it should have complained, it is already time for weeping and gnashing of teeth.
References and standards
Academic articles
- Datasheets for Datasets — Gebru et al. proposed standardized documentation for datasets, including motivation, composition, and intended uses. Read the paper
- Model Cards for Model Reporting — Mitchell et al. introduced structured documentation for ML models, including performance metrics under different conditions. Read the paper
- FAIR Principles — Wilkinson et al. established principles for making data Findable, Accessible, Interoperable, and Reusable. Read the paper
- Data Cards Playbook — the Google Research team created a practical guide for documenting datasets transparently. View the playbook
Standards
- Croissant — MLCommons developed a metadata format for ML datasets that improves discoverability and reproducibility. More information
- HuggingFace Dataset Cards — standardised documentation for datasets hosted in the HuggingFace Hub. View documentation
- Dataset Nutrition Label — the Data Nutrition Project provides a framework to evaluate the “nutrition” of datasets. Visit the project | Read the paper
Evaluation frameworks
- Ragas — open-source framework for evaluating RAG pipelines with metrics such as faithfulness, answer relevance, and context relevance. Documentation | Available metrics
- DeepEval — LLM evaluation framework including RAG-specific metrics. View repository
- LlamaIndex Evaluation — integrated evaluation module to measure retrieval and generation quality. View documentation
Leave a Reply